
The open-source release of DeepSeek-R1 has sparked widespread attention in the AI field. Its outstanding performance in tasks such as inference, mathematics, and coding, coupled with its extremely low cost, makes it a strong competitor to OpenAI. This article will thoroughly analyze the training process of DeepSeek-R1, covering performance evaluation, training methods, model distillation, and future prospects, providing a comprehensive breakdown of how this model was created.
Recently, DeepSeek released the DeepSeek-R1 model (hereafter referred to as R1), once again causing a stir in both Chinese and American internet communities:
- R1 follows the MIT License, allowing users to leverage distillation technology to train other models using R1.
- R1 has launched an API, providing users with access to its reasoning chain outputs.
- R1 performs comparably to OpenAI’s GPT-4 in tasks such as mathematics, code, and natural language inference, while smaller models even surpass OpenAI’s GPT-4-mini.
- Its language capabilities are far ahead.
- The most surprising part is that its price is only a fraction of OpenAI’s cost.
Now, let’s take a more systematic look at how R1 was created.
This article will break down R1 in terms of performance, methods, distillation, and outlook. The charts and data used are sourced from its paper: “R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.”
1. Conclusion First
Before we dive into the details, it’s worth noting: besides R1, DeepSeek has also released R1-Zero.
- R1-Zero is based on DeepSeek-V3-Base and is purely trained via RL (Reinforcement Learning) without any STF (Supervised Fine-Tuning).
- R1, on the other hand, is based on R1-Zero, starting with a cold-start fine-tuning using a small amount of high-quality manually labeled data, followed by RL training.
Effectiveness of Pure Reinforcement Learning: The training of R1-Zero demonstrated that large models can still possess powerful reasoning abilities through RL alone, without SFT. At AIME 2024, R1-Zero’s pass@1 metric improved from 15.6% to 71.0%, and after applying a majority voting strategy, it further improved to 86.7%, on par with OpenAI-o1-0912 (Table 2, p. 7).
The “Aha” Moment: During training, R1-Zero exhibited an “Aha” moment, spontaneously learning new and more effective reasoning strategies.
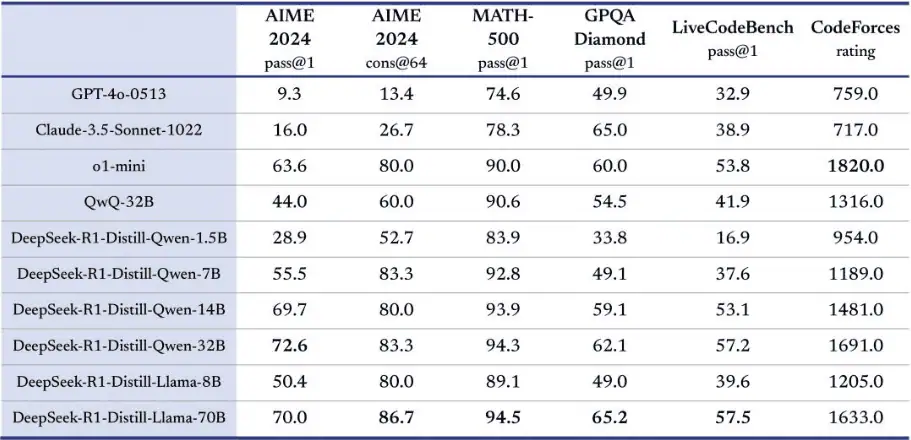
Distillation is More Effective Than Direct RL on Smaller Models: Distilling R1’s reasoning capabilities into smaller models (such as Qwen and Llama series) yields better results than directly applying RL to these smaller models (Table 5, p. 14). For example, R1-Distill-Qwen-7B scored 55.5% at AIME 2024, far surpassing QwQ-32B-Preview; R1-Distill-Qwen-32B achieved an astounding 72.6%. This shows that the reasoning patterns learned by large models during RL training are both universal and transferable.
Value of Cold-Start Data: Compared to R1-Zero, R1’s use of a small amount of high-quality cold-start data significantly improved the efficiency and final performance of RL.
2. Performance Evaluation
The paper evaluates R1’s performance across multiple dimensions, including knowledge-intensive tasks, reasoning-intensive tasks, long-text understanding tasks, and open-domain question-answering tasks, and compares it to several industry-leading baseline models.
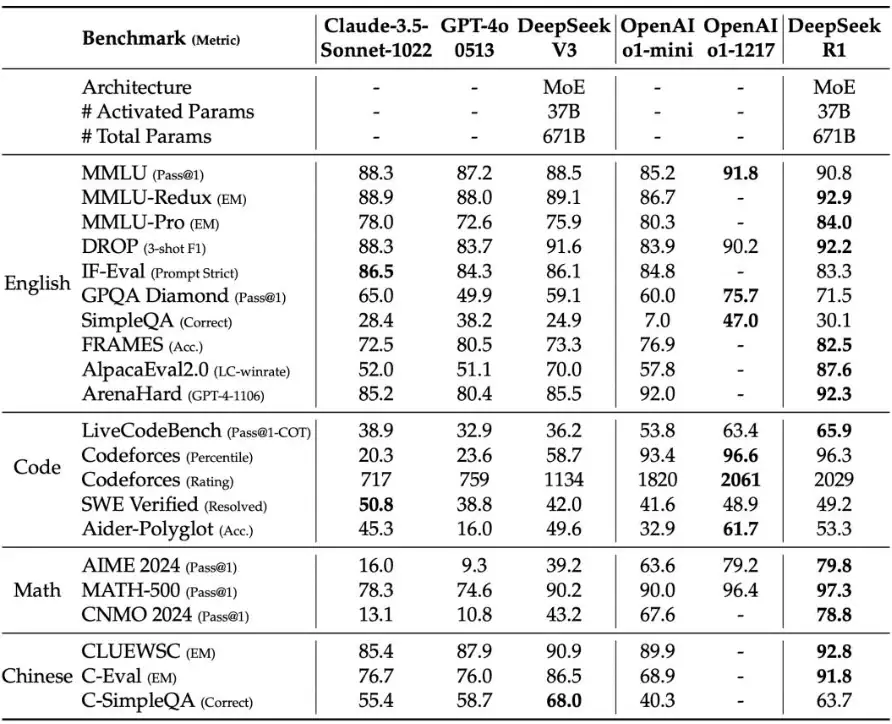
The models compared in the evaluation include DeepSeek-V3, Claude-3.5-Sonnet-1022, GPT-4o-0513, OpenAI-o1-mini, and OpenAI-o1-1217.
The table above is sourced from Above Table in the paper, and the following conclusions can be drawn:
- R1 excels in reasoning tasks, particularly in challenges such as AIME 2024 (American Invitational Mathematics Examination), MATH-500 (mathematics competition problems), and Codeforces (programming competitions), where it achieved results comparable to or even surpassing OpenAI-o1-1217.
- In knowledge-intensive task benchmarks like MMLU (90.8%), MMLU-Pro (84.0%), and GPQA Diamond (71.5%), R1 significantly outperforms the DeepSeek-V3 model.
- For long-context comprehension, in the FRAMES dataset, R1 achieved an accuracy of 82.5%, surpassing DeepSeek-V3.
- In open-domain question-answering benchmarks like AlpacaEval 2.0 and Arena-Hard, R1 scored 87.6% LC-winrate and 92.3% GPT-4-1106 score, demonstrating its strong capabilities in the open-domain Q&A domain.
3. Training Process of DeepSeek R1
1. DeepSeek R1-Zero
- Architecture Concept: A purely reinforcement learning (RL) training model, without any SFT data, relying entirely on pure RL.
- Algorithm Application: Directly applies the GRPO algorithm for reinforcement learning training on the DeepSeek-V3-Base model.
- Reward Mechanism: A rule-based reward system, including accuracy rewards and format rewards, is used to guide the model’s learning.
- Training Template: The model is required to first output the reasoning process (within a tag), followed by the final answer (within a tag).


“Aha” Moment: During the training of R1-Zero, a notable “Aha” moment occurred. For example, in Table 3 (p. 9), a middle-stage output from R1-Zero shows how the model, while solving a math problem, suddenly realized it could “re-evaluate” previous steps and attempt a new method to solve the problem.
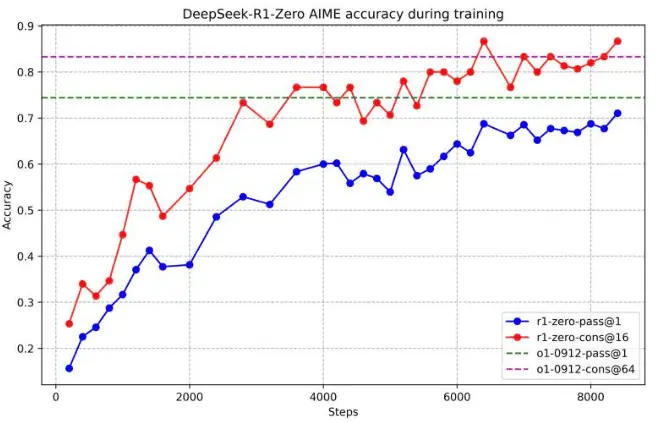
Performance: The performance curve of R1-Zero on the AIME 2024 benchmark shows a steady improvement in the pass@1 metric, rising from an initial 15.6% to 71.0% during RL training, reaching a level comparable to OpenAI-o1-0912 (Figure 2, p. 7).
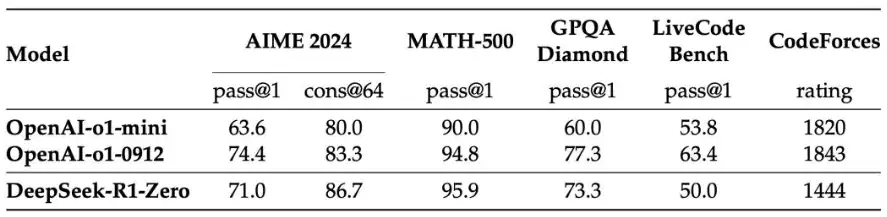
In tasks like AIME 2024, MATH-500, and GPQA Diamond, R1-Zero achieved results comparable to OpenAI-o1-0912, with some tasks even showing significant lead (Table 2, p. 7).
2. R1
- Architecture Concept: Based on the DeepSeek-V3-Base model, R1 first undergoes fine-tuning with a small amount of high-quality “cold-start” data, followed by reinforcement learning. This approach combines the advantages of supervised learning and reinforcement learning, allowing the model to be guided by human prior knowledge and leverage RL’s self-learning and self-evolution capabilities.
- Cold Start Phase: Thousands of high-quality manually labeled samples are used to fine-tune the DeepSeek-V3-Base model as the initial model for RL training. To construct high-quality cold-start data, the DeepSeek team experimented with several methods, including:
- Using few-shot prompting with long CoT (Chain of Thought).
- Directly prompting the model to generate detailed answers with reflection and validation.
- Collecting outputs from R1-Zero and manually annotating and formatting them.
- Reinforcement Learning for Reasoning: After the cold-start phase, R1 adopts a reinforcement learning training process similar to R1-Zero, but with special optimizations for reasoning tasks. To address potential language mixing issues during training, R1 introduces a Language Consistency Reward, calculated based on the ratio of the target language words in the CoT.
- Rejection Sampling and Supervised Fine-Tuning (SFT): Once RL training for reasoning converges, R1 uses the trained RL model for rejection sampling to generate new SFT data. Unlike the cold-start data, this phase’s SFT data includes not only reasoning tasks but also other areas like writing, role-playing, and question-answering, enhancing the model’s general capabilities.
- Full-Spectrum Reinforcement Learning: After collecting the new SFT data, R1 undergoes a second phase of reinforcement learning training. This time, the training is no longer limited to reasoning tasks but spans all task types. R1 uses different reward signals and prompt distributions, optimized for different task types. For example, rule-based rewards are used for tasks like mathematics, coding, and logical reasoning, while model-based rewards are used for open-domain Q&A, creative writing, and other tasks.
4. Core Methods
1. GRPO
The core algorithm used in R1 is Group Relative Policy Optimization (GRPO), complemented by a carefully designed reward mechanism to guide the model’s learning. Unlike traditional algorithms that require constructing a Critic model to estimate state value functions, GRPO estimates the advantage function (Advantage) by comparing rewards from a set of samples. This approach reduces the complexity of the training process and the computational resources required. The objective function and advantage function calculations for the GRPO algorithm are described in detail in section 2.2.1 of the paper (p. 5).
.webp)
2. Reward System
R1-Zero’s reward system mainly consists of two types:
- Accuracy Rewards: Evaluates whether the model’s generated response is correct. For tasks with deterministic answers (e.g., mathematical problems), the model is required to place the final answer in a specific format (e.g., inside a box) for automatic validation. For code generation tasks (e.g., LeetCode problems), a compiler is used to test the generated code.
- Format Rewards: Forces the model to place the reasoning process between the “think” and “think” tags to facilitate the analysis and understanding of the model’s reasoning process.
3. Training Template
R1-Zero uses a simple training template (Table 1, p. 6), which requires the model to first output the reasoning process, followed by the final answer. The template is as follows:
Where the prompt will be replaced with a specific reasoning problem during training.
5. Model Distillation
The DeepSeek team further explored the possibility of distilling R1’s reasoning capabilities into smaller models. They fine-tuned several smaller models from the Qwen and Llama series using 800K data generated by R1. The results of the model distillation are shown in Table 5 (p. 14).
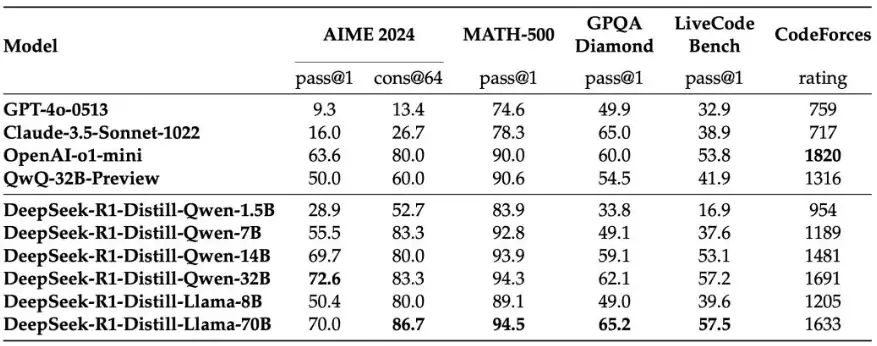
The following conclusions can be drawn:
- Distilled models show significant improvement in reasoning abilities, even surpassing the results of directly applying reinforcement learning on these smaller models. For example, R1-Distill-Qwen-7B scored 55.5% on AIME 2024, far surpassing QwQ-32B-Preview.
- R1-Distill-Qwen-32B scored 72.6% on AIME 2024, 94.3% on MATH-500, and 57.2% on LiveCodeBench. These results significantly outperform previous open-source models and are on par with OpenAI’s o1-mini.
- Table 6 (p. 14) compares the performance of R1-Distill-Qwen-32B and R1-Zero-Qwen-32B. The results show that directly applying reinforcement learning to Qwen-32B-Base only achieves performance comparable to QwQ-32B-Preview, while the distilled R1 model significantly outperforms both. This indicates that the reasoning patterns learned by R1 are highly generalizable and transferable, and can be passed on to other models through distillation.

6. More to Explore
At the end of the paper, the DeepSeek team discusses the limitations of the R1 model and outlines potential future research directions:
Limitations:
- General Abilities: R1’s general abilities (such as function calls, multi-turn dialogue, complex role-playing, and JSON output) still lag behind DeepSeek-V3.
- Language Mixing: R1 may experience language mixing when handling non-Chinese or non-English tasks.
- Prompt Engineering: R1 is sensitive to prompts, and using few-shot prompting may reduce its performance.
- Software Engineering Tasks: Due to the long evaluation cycles in RL training, R1’s performance improvement in software engineering tasks is limited.
Future Work:
- Explore how to improve R1’s general abilities by leveraging long CoT (Chain of Thought).
- Address the language mixing issue in R1.
- Optimize R1’s prompt strategy.
- Apply RL to software engineering tasks to improve R1’s performance in that domain.
- Continue exploring more effective reinforcement learning algorithms and reward mechanisms to further enhance the model’s reasoning capabilities.
- Investigate how to better apply R1’s reasoning abilities in practical scenarios such as scientific research, code generation, drug discovery, and more.
Additional Insights:
The DeepSeek team also experimented with other methods during their research, though these did not yield the desired results:
- Process Reward Model (PRM): The construction and training of PRM posed significant challenges and often led to reward “hacks.”
- Monte Carlo Tree Search (MCTS): MCTS faced issues with an overly large search space in token generation tasks, and the training of the value model was difficult.
Source: https://arxiv.org/abs/2501.12948

Disclaimer:
- This channel does not make any representations or warranties regarding the availability, accuracy, timeliness, effectiveness, or completeness of any information posted. It hereby disclaims any liability or consequences arising from the use of the information.
- This channel is non-commercial and non-profit. The re-posted content does not signify endorsement of its views or responsibility for its authenticity. It does not intend to constitute any other guidance. This channel is not liable for any inaccuracies or errors in the re-posted or published information, directly or indirectly.
- Some data, materials, text, images, etc., used in this channel are sourced from the internet, and all reposts are duly credited to their sources. If you discover any work that infringes on your intellectual property rights or personal legal interests, please contact us, and we will promptly modify or remove it.






