
With the development of large-scale language models, led by ChatGPT, a variety of applications such as ChatPDF, BingGPT, NotionAI, and more have emerged. While the public heavily focuses on the rapid progress of generative models, there is little attention paid to the essential Embedding models that support many large-scale language model applications. This article will mainly introduce why Embedding models are crucial in large language models, the current mainstream Embedding training methods, and some of our thoughts on the preliminary exploration of Embedding models.
01
The Introduction and Historical Overview of Embedding Technology
In machine learning and natural language processing, an Embedding model refers to the process of mapping high-dimensional data (such as text, images, and videos) into a lower-dimensional space. Simply put, an embedding vector is an N-dimensional real-valued vector that represents the input data as a point in a continuous numerical space. This article mainly focuses on text embedding.
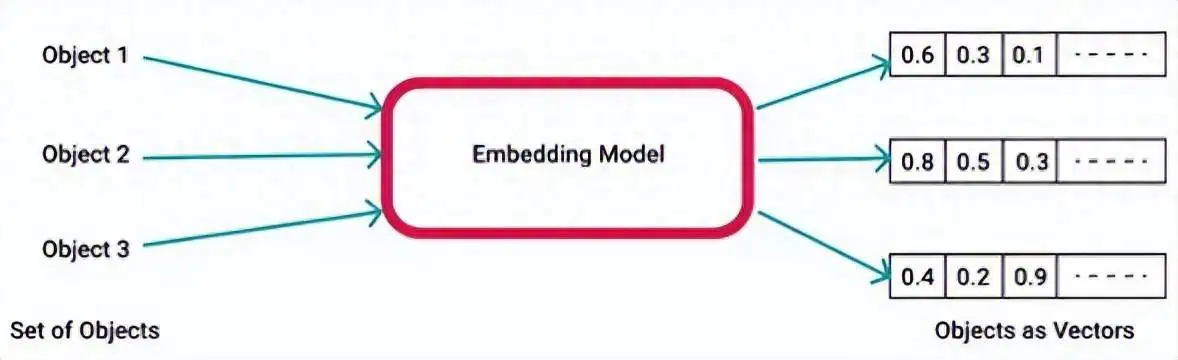
The significance of Embedding lies in its ability to represent the semantics of words or sentences. Real-valued vector embeddings can represent the semantics of words mainly because these embedding vectors are learned based on the occurrence patterns of words in linguistic contexts. For instance, if a word frequently appears together with another word in certain contexts, then the embedding vectors of these two words will have similar positions in the vector space. This implies that they have similar meanings and semantics.
The concept of Embedding can be traced back to the mid-20th century when Harris proposed the theory of distributed semantics. By the 1980s, people began attempting to use neural networks to learn embeddings for words. Since 2010, with the development of deep learning techniques, there have been static vector embeddings represented by Word2Vec, GloVe, FastText, and dynamic vector embeddings that capture contextual information using ELMo, GPT, and BERT, among others. The latter can better capture the semantics of words in context.
02
The Value of Embedding in Large Language Models
As mentioned earlier and commonly acknowledged, embedding vectors encapsulate semantic information, with closer meanings correlating to closer positions of embedding vectors within the space. Real-valued vector embeddings learn the semantics and contextual information of words from extensive data, enabling vector operations and sharing/transferring across various natural language processing tasks.
However, what new value does Embedding offer in the era of large language models?
This leads to the shortcomings of models like ChatGPT. Despite their immense capabilities, they currently face several issues:
- Non-Real-Time Training Data: (e.g., ChatGPT is trained on data up to September 2021), retraining is costly and impractical.
- Input Text Length Limitation: Typically restricted between a few thousand to tens of thousands of tokens.
- Inability to Access Non-Public Documents.
Addressing these concerns, OpenAI released a document detailing how to use embedding-based two-step searching to tackle GPT’s inability to handle long texts and up-to-date data. This two-step search involves initially scouring the text corpus to find relevant text segments and then adding these retrieved text parts to the input of GPT-like models to generate responses.
Illustrating this with a representative application: when desiring a large model to provide answers based on a given PDF document, the approach involves chunking the lengthy PDF into segments, obtaining embeddings for each segment, and storing these in a vector database. Subsequently, when you pose a query such as “How is xxx implemented in the document?”, the system uses the embedding of your question to search the database for the most similar embedding representing a part of the PDF content. Ultimately, it inputs the retrieved PDF content segment along with the question into the model to address issues related to new knowledge and inputting extremely long texts.
Therefore, although the current discussions might not emphasize it, exploring embedding models is indispensable for the practical implementation of large language models.
03
Mainstream Embedding Training Methods
As mentioned earlier, OpenAI has introduced an Embedding-based search solution to address issues with long text input and the incorporation of current data. Naturally, OpenAI also has an undisclosed training method for Embedding called text-embedding-ada-002. This represents OpenAI’s second-generation Embedding model, capable of simultaneously handling three downstream tasks—text search, text similarity, and code search—using a single model. Compared to the first-generation model, which employed five separate models for these tasks, the second-generation model is streamlined into a single model and demonstrates good performance in both Chinese and English tasks.
In this section, we’ll outline some mainstream Embedding training methods. In recent years, most work related to Sentence Embedding has been based on BERT-like models. Extracting embeddings from models based on the Decoder structure has limited research with publicly available code. Details about the training of Embedding models in OpenAI’s published papers are also not entirely clear. Therefore, in this chapter, we will primarily summarize some representative methods of Sentence Embedding based on BERT-like models. Further discussion on exploring the extraction of embeddings from models based on the Decoder structure will be addressed in Chapter Four.
Before the era of BERT, word embeddings trained using word2vec combined with pooling strategies were commonly used to represent sentence vectors. In the BERT era, leveraging the inherent advantages of pre-trained language models, people initially used the [CLS] vector of the BERT model as the representation of sentence vectors. Subsequently, Sentence-BERT cleverly employed a Siamese network framework to obtain sentence vectors. Following this, there emerged works such as BERT-Flow, BERT-Whitening, SimCSE, R-Drop, and ESimCSE, among others. Among these, BERT-whitening and SimCSE gained more recognition. Later, numerous works focused on contrastive learning as a primary approach, making improvements in constructing positive and negative sample pairs at the data level and during training. This chapter aims to provide a summary of such methods.
Given that recent work on Sentence Embedding has revolved around contrastive learning, let’s first recall the basics of contrastive learning.
🔹Comparative learning background
Comparative learning is ‘aiming to bring similar data closer and dissimilar data farther away, effectively learning data representations.’ Given a pair of sample sets, where there is a similar sample, the optimization goal generally adopts the in-batch negative cross-entropy loss function as follows:
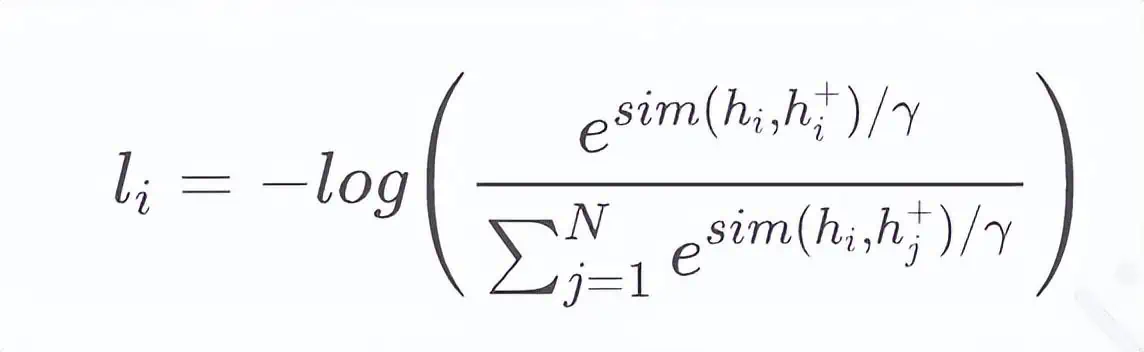
Where is the sentence vector representation of, N is the size of the batch during the training process, is the vector sum and cosine similarity, and is the temperature hyperparameter.
🔹Classic Methods
In recent years, since the emergence of SimCSE, there has been a small wave of research in the field of sentence embeddings. In this section, we primarily conducted a relatively detailed review of three works from a similar period as SimCSE (SimCSE, ESimCSE, CoSENT), and briefly summarized subsequent representative works.
🔹SimCSE
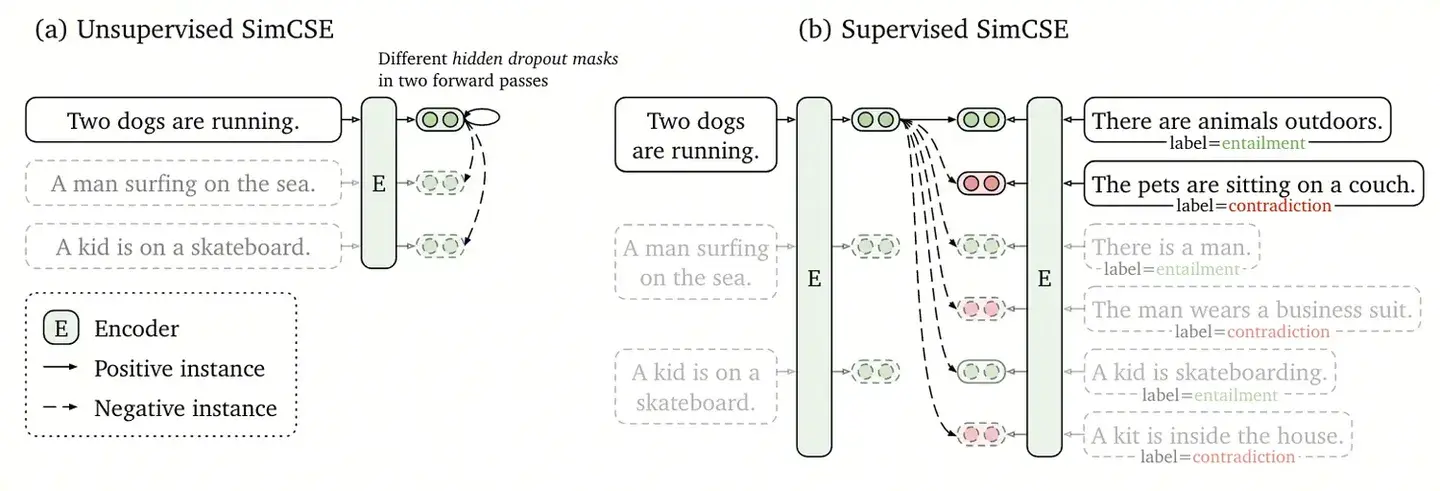
SimCSE is considered one of the standout works in the field of sentence embeddings.
It is divided into two versions:
- The unsupervised version of SimCSE: Positive samples come from two similar representations generated by applying different dropout masks to the same sentence, while negative examples use in-batch negatives.
- The supervised version of SimCSE is based on NLI (Natural Language Inference) datasets to construct positive and negative samples. Positive examples consist of sentence pairs with entailment relationships, while negative examples consist of sentence pairs with contradiction relationships (difficult negatives) and in-batch negatives.
The above encapsulates the core idea of SimCSE, which is simple, effective, and simultaneously very inspiring. It has led to a subsequent wave of research in sentence embedding technology.
🔹ESimCSE
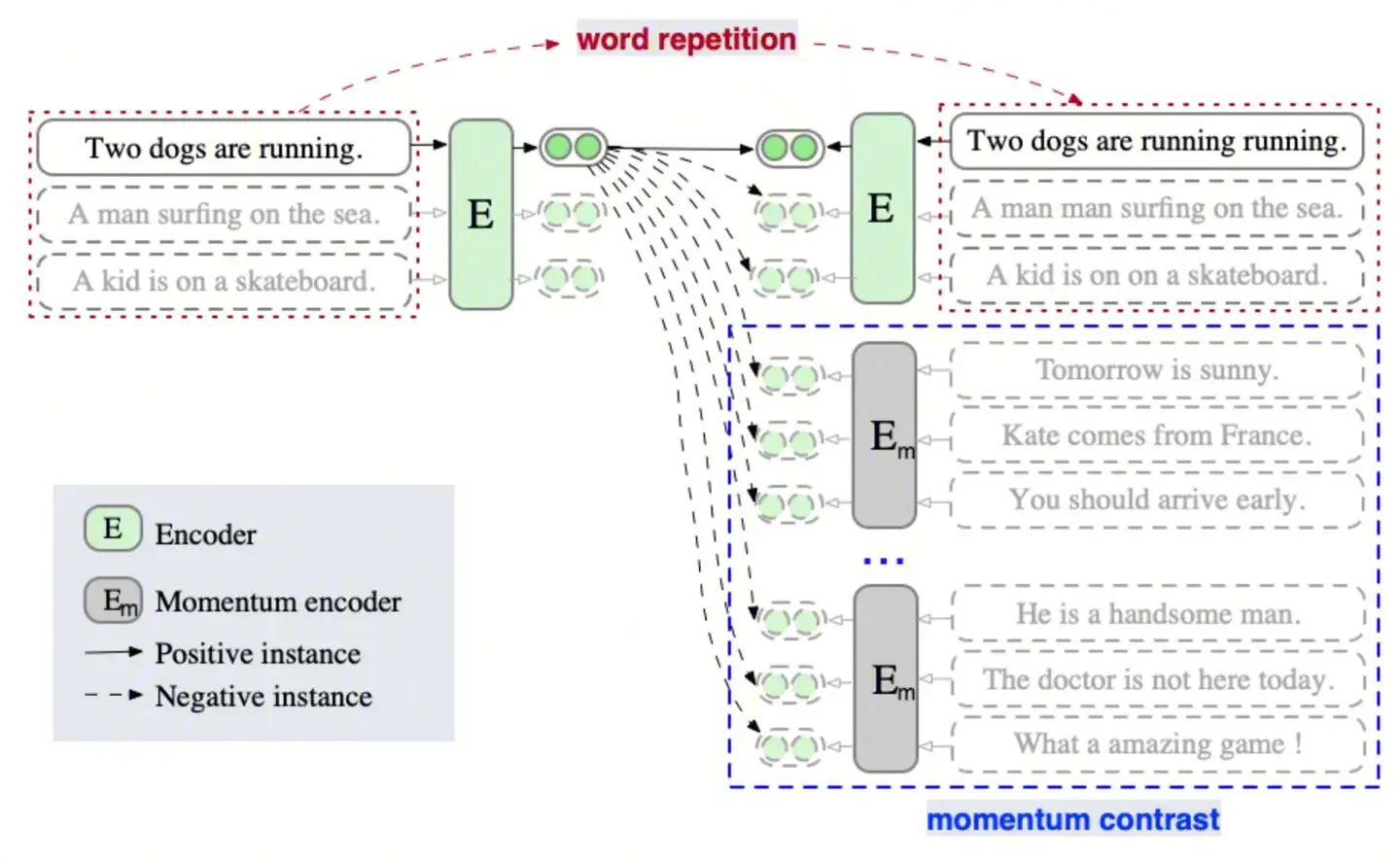
ESimCSE has made improvements to SimCSE from the perspectives of constructing positive and negative samples:
(1) Construction of positive sample pairs:
While SimCSE constructs positive pairs by adjusting dropout rates, resulting in pairs of equal length, the negative pairs have unequal lengths. This tendency might lead the model to favor judgments that sentences of similar or the same length are more similar in representation.
To alleviate this issue, ESimCSE chooses to randomly duplicate some words within sentences. This adjustment allows for changes in sentence length without altering their semantics.
(2) Construction of negative sample pairs:
In contrastive learning, theoretically, the more negative pairs, the better the comparison between pairs. ESimCSE adheres to this idea but doesn’t aggressively increase the batch size. Instead, it maintains a queue and reuses the encoded embeddings of the preceding mini-batch to expand negative pairs, utilizing a momentum encoder. The specific approach involves taking the moving average of the parameters of queued sentence embeddings to preserve momentum-updated models and using the momentum model to generate queued sentence embeddings. When using the momentum encoder, dropout is turned off to reduce the gap between training and prediction. The parameters of the encoder and the momentum-updated encoder are updated according to the formula:
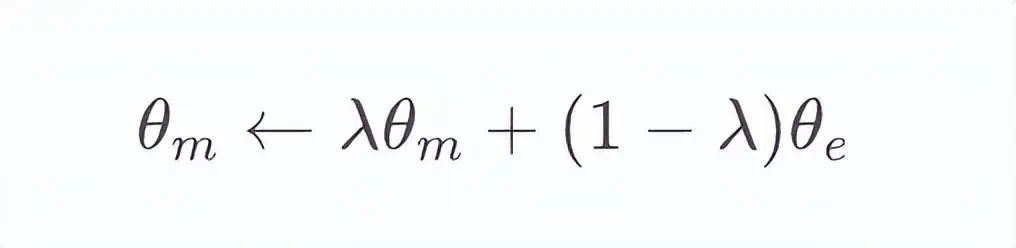
where is the momentum coefficient parameter. It’s important to note that only parameters are updated through backpropagation. Here, we introduce momentum to generate sentence embeddings for the queue, making updates smoother than evolution. Hence, although the embeddings in the queue are encoded by different encoders (in different “steps” during training), the differences between these encoders can be minimal.
🔹CoSENT
The early Sentence-BERT had problems with inconsistent training, prediction, and difficulty in fine-tuning. However, if directly optimizing the cosine value target, the effect often turns out to be particularly poor. Does this mean that there is no hope for a direct optimization of the cosine value?
Fortunately, the answer is no. Professor Su Jianlin proposed a CoSENT solution, a loss function that optimizes the cosine value:
Given a set of all positive sample pairs and a set of all negative sample pairs, we hope that for any positive sample pair and negative sample pair, we have:
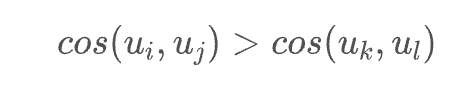
Where and are their respective sentence vectors? In simple terms, we only hope that the similarity of positive sample pairs is greater than that of negative sample pairs. As for how much greater, the model decides. The commonly used semantic similarity evaluation index, Spearman, operates similarly; it depends only on the relative order of predictions rather than specific values.
For such requirements, the formula from the Circle Loss theory can be used as a solution:
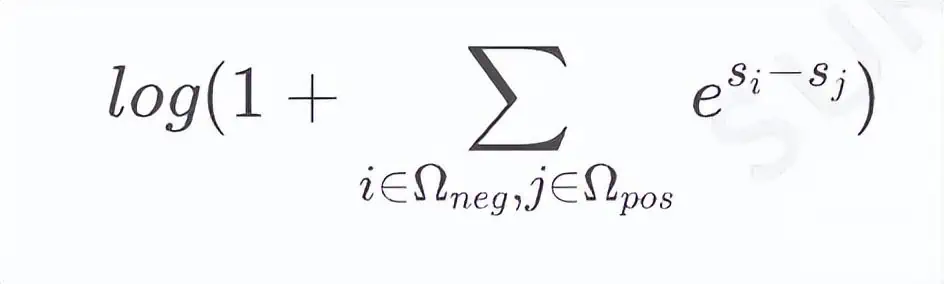
Simply put, if the final goal is desired, then add a term inside the logarithm. Corresponding to our scenario, we can obtain the loss function:
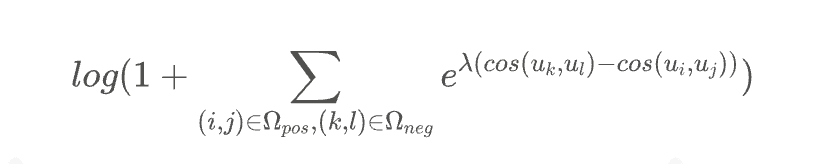
Where is a hyperparameter? The above formula is essentially a loss function designed for sorting, also applicable to multi-class data, expressed in a more general form:
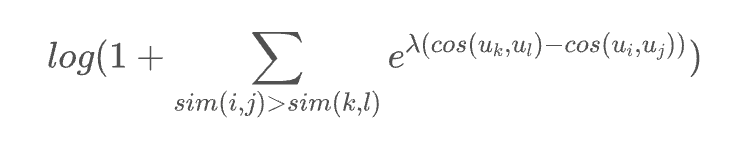
In other words, as long as we believe that the true similarity of the sample pair (i, j) should be greater than the true similarity of the pair (k, l), we can add it to the logarithm. In other words, as long as we can design an order for sample pairs, the CoSENT solution can be used.
For NLI data, it has three labels: ‘entailment’, ‘neutral’, and ‘contradiction’. Naturally, we can assume that the similarity of two ‘entailment’ sentences is greater than two ‘neutral’ sentences, and the similarity of two ‘neutral’ sentences is greater than two ‘contradiction’ sentences. This way, based on these three labels, the sentences in NLI can be sorted. With this sorting, NLI data can also be trained using CoSENT. Similarly, for datasets like STS-B that are inherently scored, CoSENT is more suitable as scoring labels themselves contain sorting information.
🔹Summary of the subsequent works
- SNCSE: Contrastive Learning for Unsupervised Sentence Embedding with Soft Negative Samples
- Addresses the problem of models being unable to distinguish between text similarity and semantic similarity, leaning more towards similar text without considering actual semantic differences.
- Proposes a solution by “explicitly adding negation words to generate soft negative samples” combined with “bidirectional margin loss.”
- EASE: Entity-Aware Contrastive Learning of Sentence Embedding
- Emphasizes the importance of entities in sentence vector representation.
- On a data level, use positive and negative entities instead of positive and negative samples.
- CLAIF: Improving Contrastive Learning of Sentence Embeddings from AI Feedback
- Targets the lack of fine-grained supervision signals during the training process, specifically the oversight of differences in similarity between positive sample pairs.
- Introduces AI feedback from LLM (Language Model) to construct sample pairs with varying degrees of similarity and provides fine-grained similarity scores for these pairs as supervision signals to aid in learning text representations.
🔹PromptBERT
The article about PromptBERT is another classic in the field of sentence embeddings following SimCSE.
The core idea of this work revolves around using prompts to generate sentence representations. The authors believe that the underperformance of native BERT is mainly due to biases introduced by factors like word frequency, casing, and subword tokens, and these biases aren’t corrected across the Transformer layers in BERT. By leveraging prompts, it becomes more efficient to utilize the knowledge within various layers of BERT. Additionally, representing embeddings using ‘[MASK]’ helps avoid biases introduced by previous practices, such as averaging various tokens.
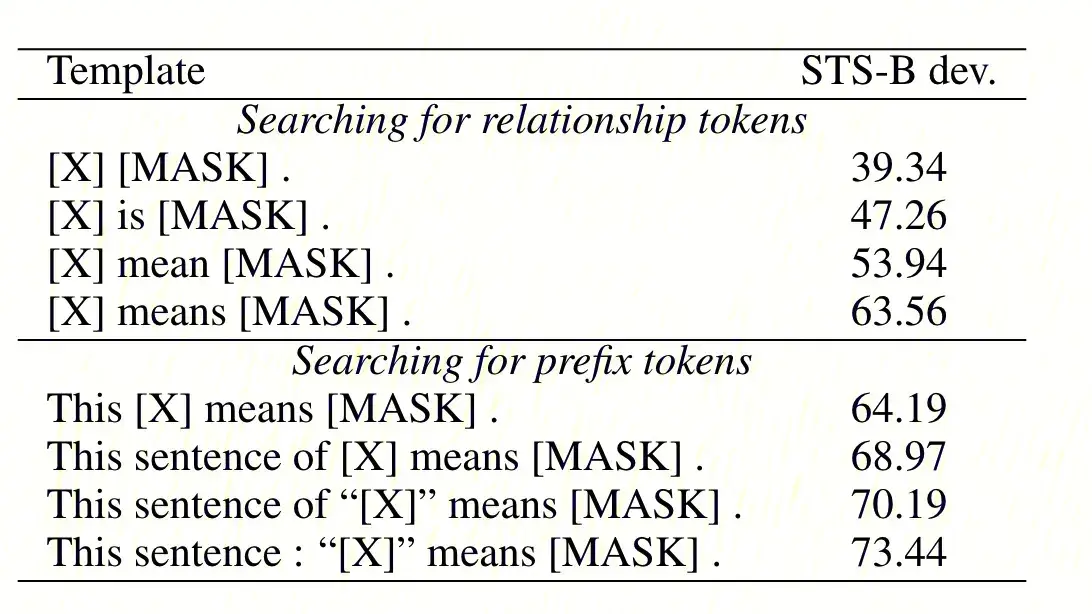
The fundamental approach of this work is relatively straightforward and involves two steps:
- Generating sentence representations using the prompt format, for instance, ‘[X] means [MASK]’, where ‘[X]’ represents the input sentence and ‘[MASK]’ denotes the output representation, thereby using it as the sentence representation.
- Employing different prompt templates to generate contrasting perspectives for continued self-supervised training through contrastive learning.
🔹Instructor Embedding
According to OpenAI’s paper titled “Text and Code Embeddings by Contrastive Pre-Training,” it’s noted that text similarity and semantic retrieval are two distinct tasks, and the training objectives might have certain conflicts. As training progresses, if a model excels more in semantic search tasks, its performance in sentence similarity tasks might diminish. Additionally, existing embedding models often exhibit poor performance when faced with new tasks and domains.
An ideal embedding should possess multiple capabilities simultaneously. How can embedding models adapt to multiple tasks while demonstrating generalizability in new domains?
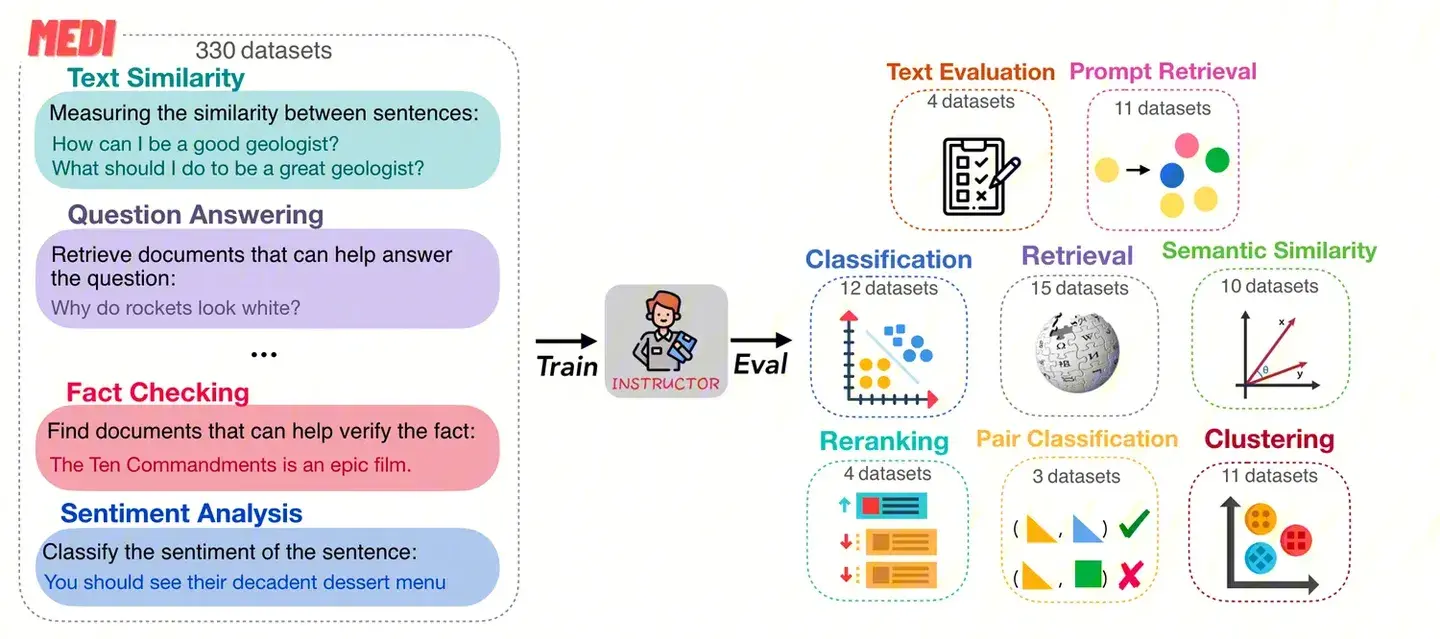
“Instructor Embedding” introduces a novel approach to text embedding based on instruction-guided fine-tuning. It involves concatenating instructional guidance—comprising task and domain information—before the input of the text. During training, Instructor Embedding manually curates instructional guidance for 330 text embedding datasets and evaluates “INSTRUCTOR” across 70 embedding evaluation tasks (with 64 tasks unseen during training). These tasks span from classification and information retrieval to semantic text similarity and text generation assessment, achieving overall commendable performance.
04
Exploration and Thinking Related to Embedding
The previous chapter outlined the representative work of Sentence Embedding based on BERT-like models. It seems reasonable for BERT-like models that use bidirectional attention mechanisms to excel in content-understanding tasks. However, the effectiveness of OpenAI’s Embedding model, the degree of OpenAI’s commitment to the Decoder-Only architecture model, and the rapid development of large models in the past six months have made us curious: Can Decoder-Only large models also surprise us in Embedding tasks?
We conducted some exploratory attempts in this regard. In the process of exploration, we most hoped to clarify two questions:
- Is it true that BERT-like models are inherently more suitable for Embedding tasks than Decoder-Only architecture models?
- Is it the case that, for Embedding tasks, the larger the model, the better?
In the end, after we explored the padding method, pooling method, and different layers’ degree of anisotropy for Decoder-only models, the conclusion we reached was relatively consistent with the currently partially publicized conclusions.
Regarding the first question, the research paper “How Contextual are Contextualized Word Representations? Comparing the Geometry of BERT, ELMo, and GPT-2 Embeddings” conducted experiments comparing the effects of different layers of BERT and GPT, as shown in the following table.
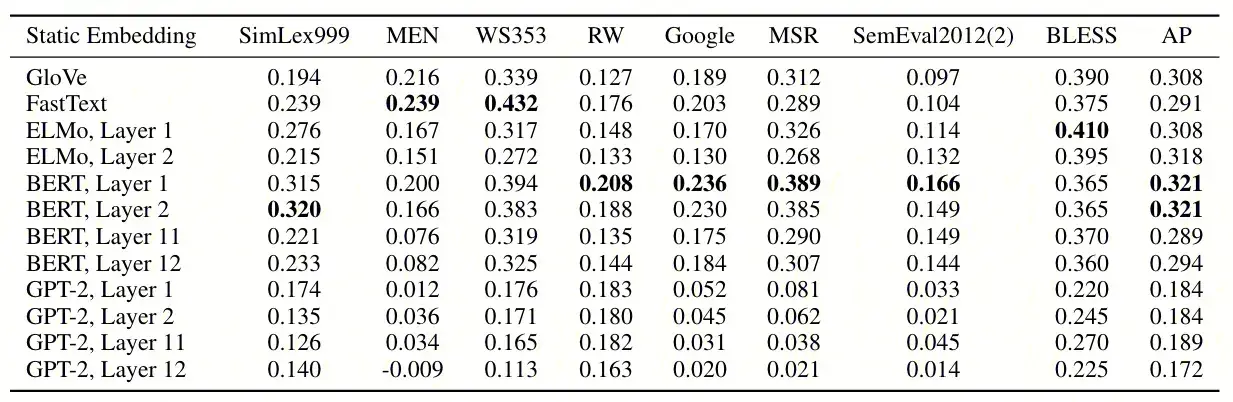
Based on the above table, we can observe:
- Across different layers, BERT’s overall performance is significantly better than GPT.
- The anisotropy of GPT-2’s last layer is relatively severe, suggesting that middle or lower layers are more suitable for similarity tasks than the top layer.
Regarding the second question, the Instructor Embedding paper also provides comparative experiments on the effectiveness of models with different parameter quantities, as shown in the following table:
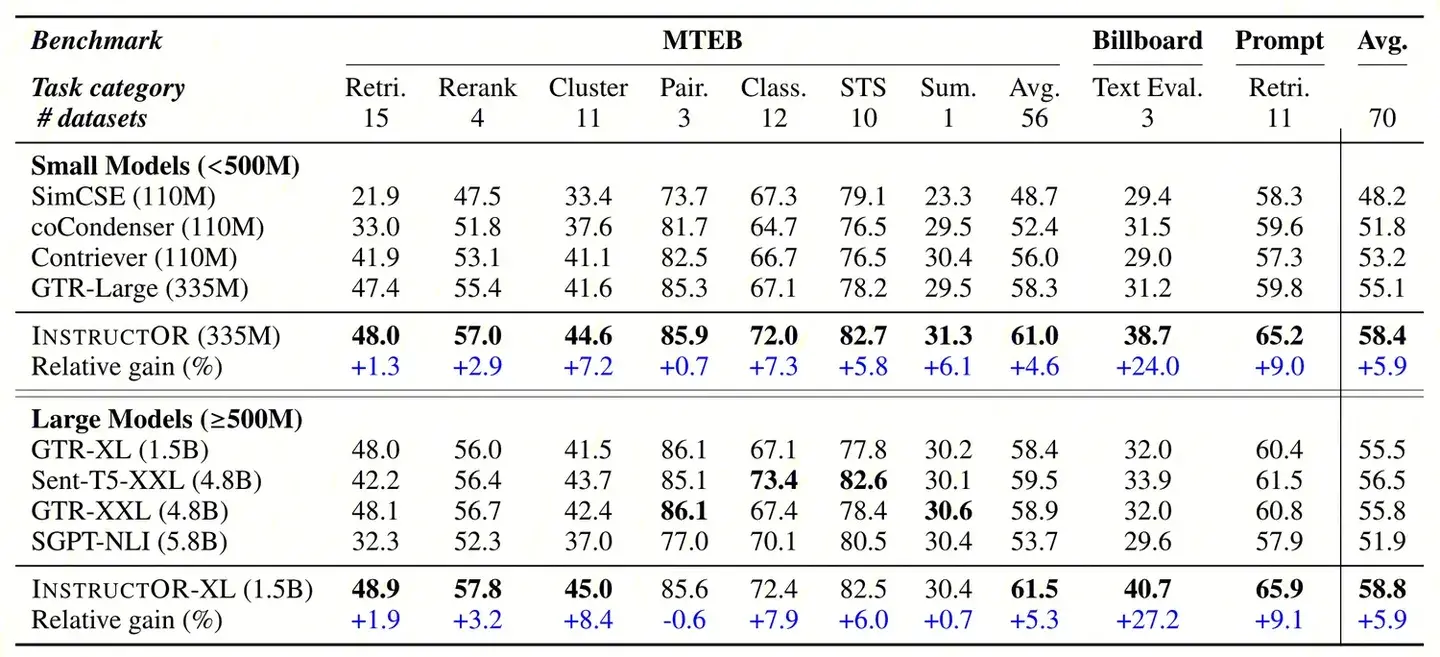
Based on the above table, we can observe:
- The performance of the 4.8B GTR-XXL model, with parameter quantities tens of times larger than the 335M GTR_LARGE model, does not show a significant improvement.
- The 5.8B SGPT-NLI model based on the Decoder-Only architecture is outperformed by the Encoder-Only architecture of the 4.8B GTR-XXL model with similar parameter quantities.
In summary, considering our experiments, the initial conclusions are:
- From the perspective of model parameter quantity: Increasing the model’s parameter quantity does not necessarily guarantee an improvement in performance in Embedding tasks.
- From the perspective of model structure: Based on our current experimental results, BERT-like models with bidirectional attention indeed demonstrate better performance compared to Decoder-only structures with unidirectional attention.
However, since OpenAI has not publicly disclosed the technical details of their Embedding solution, perhaps we have yet to discover the correct approach to using GPT for Embedding. Interested individuals are welcome to further discuss this matter.
Related:

Reference:
- SimCSE: Simple Contrastive Learning of Sentence Embeddings
- ESimCSE: Enhanced Sample Building Method for Contrastive Learning of Unsupervised Sentence Embedding
- SNCSE: Contrastive Learning for Unsupervised Sentence Embedding with Soft Negative Samples
- EASE: Entity-Aware Contrastive Learning of Sentence Embedding
- PromptBERT: Improving BERT Sentence Embeddings with Prompts
- Improving Contrastive Learning of Sentence Embeddings from AI Feedback
- Text and Code Embeddings by Contrastive Pre-Training
- One Embedder, Any Task: Instruction-Finetuned Text Embeddings
- 苏剑林. (Jan. 06, 2022). 《CoSENT(一):比Sentence-BERT更有效的句向量方案 》[Blog post]. Retrieved from https://kexue.fm/archives/8847
- How Contextual are Contextualized Word Representations? Comparing the Geometry of BERT, ELMo, and GPT-2 Embeddings
- SGPT: GPT Sentence Embeddings for Semantic Search
- Author: kaili






