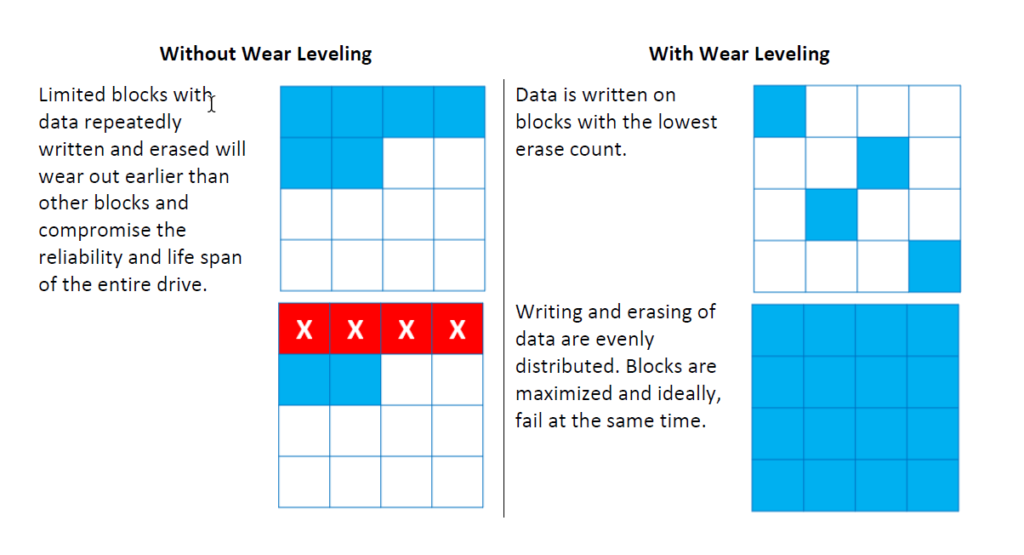
In order to make flash memory have a longer lifetime, some blocks can be erased frequently and quickly become worse, while others can be erased imbalanced so that the SSD lifetime is shortened. Flash practitioners have proposed a variety of Wear-Levelling algorithms and Garbage Collection strategies to avoid these problems.
Background of the wear balancing algorithm
The wear balancing algorithm is based on the basic characteristics of flash memory:
- The local update is not supported (outplace-update cannot be overwritten or directly changed in the original data location, the changed data needs to be moved to a new available page, and the original location of the page is marked as an invalid page, you must first erase the invalid page before writing data in the original location);
- Write in pages and erase in blocks. To erase blocks, data in available pages must be moved first.
- Each Block has a limit on the number of erasure times, and frequently erasure blocks will quickly become bad blocks. Therefore, only balancing the erasure times of each Block can make flash memory have a longer service life.
FTL typically classifies pages into three types: Valid page, Invalid Page, and Free Page. If a physical page has a logical address corresponding to it, the page data is valid. Otherwise, the page is invalid. Before data can be written again.
When logical address, for example, A corresponding physical addresses (assuming that 1) the data need to be modified, not directly to A change of address data, need to be modified in A read address data to the cache, then the modified data to the new physical address (assuming the physical address 6), at the same time will be A logical address corresponding to physical addresses (6), TRIM marks physical address 1 as an invalid page. When fewer pages are available, Garbage Collection starts to Erase the invalid pages and make them available again.
Because Erase is a unit of blocks, if the Block to be erased still contains valid pages, the valid pages must be moved before they can be erased. Do you Erase the blocks that have the fewest valid pages or the blocks that have more valid pages but less erasure? Is the number of erasure times of the Block where the effective Block cold data resides considered? Or do I erase some blocks conditionally? Since the garbage collection is directly related to the number of blocks erased, the abrasion balancing algorithm is developed in the context of how each Block can be erased equally, instead of some blocks containing hot data being erased frequently and others being erased rarely.
Garbage Collection strategy
The so-called wear balance refers to which blocks are garbage collected during the garbage collection process and which mechanism is used to ensure that each Block is erased nearly evenly.
A simple collection strategy can shorten the time required to calculate the collection of blocks but will result in uneven wear on each Block. Complex recovery strategies balance algorithms but reduce system efficiency. Therefore, a good recovery strategy needs to balance the delicate relationship between system efficiency and wear times.
Garbage collection strategies range from the basic Greedy algorithm (select blocks containing the least number of valid pages for collection) to the progressive cost-benefit algorithm (consider the erase frequency of blocks, i.e. the effect of hot and cold data), as follows:

As for the CAT recovery algorithm, the factor of the erasing times of blocks is considered on the basis of cost-benefit. The blocks to be recycled are determined by the algorithm, and the one with the smallest value is selected for recycling. The formula is as follows:

Furthermore, the CICL algorithm further optimizes, and the blocks to be recovered are determined by two factors: the number of valid pages in the Block and whether the number of erasers of all blocks is equal. L is the weight to determine these two factors. If the average erasers of all blocks are the same, l is 0. Only the number of valid pages in the Block needs to be considered when selecting a Block to recycle; otherwise, these two factors need to be considered. The formula is as follows:

Based on the basic idea of the garbage collection strategy mentioned above, various Controller manufacturers have evolved a variety of different garbage collection algorithms, as well as the analysis methods of hot and cold data.
Passive recovery strategy and active recovery strategy
There are two important issues to consider in garbage collection: when invalid blocks are collected and how many are collected at a time. Therefore, there are two recycling strategies: active recycling strategy and passive recycling strategy.
When receiving a written request, the system determines whether to perform garbage collection based on the current status. In this policy, the system sets a threshold for the available space and starts garbage collection when the available space is smaller than the threshold. How much space needs to be reclaimed each time is up to the Firmware engineer.
The downside of this attesting is that when garbage collection is performed, write requests are delayed, and the more blocks that need to be collected at a time, the longer the delay, which is represented by a sharp drop in write performance. For ordinary users, the system will feel stutter or suspended animation, while for data collection users, there will be a lot of frame loss in the garbage collection process.

The active recovery strategy is to use the idle time of the system to perform garbage collection, set periodic tasks through the firmware, periodically check the remaining status of available blocks, and perform garbage collection if necessary. The active collection strategy is equivalent to using idle time to collect garbage in advance, avoiding the performance fluctuation caused by the passive strategy.
Using the system’s idle time to implement active garbage collection also has disadvantages. Assuming that the system has no idle time, garbage collection cannot be effectively implemented, for example, video monitoring of city roads, flash memory will always have files written. In this case, garbage collection and passive strategy are basically the same.
DiskMFR uses a more optimized approach in its active recycling strategy: PR-Latency technology. At the same time, depending on the application scenario, with automatically adjustable OP space, the SSD can maintain the same performance even under 100% write/read load, using IOMeter to set a 2MB pattern and 100% write mode for Uninterrupted testing, a week after the direct test performance curve, can still perform as a straight line.

Static wear balance and dynamic wear balance
Dynamic wear balance refers to when the need to change some data on a page, the new data is written to erase fewer physical pages, at the same time the original marked invalid pages, dynamic wear balance algorithm’s disadvantage is that if you just write the data to be updated again soon, so, just updated data block page soon become invalid, if update frequently, Undoubtedly, blocks that hold cold data are rarely erased, adversely affecting the overall life of flash memory. The early SSD main control used a dynamic wear balance algorithm, now more research on dynamic and static use together.
Static wear equilibrium takes into account blocks with low update frequency (cold data), for example, The Block where the system data resides or some read-only data is updated at a much lower frequency than the Block where the hot data resides. The static wear balancing algorithm adds the blocks where the cold data resides to the wear balancing, increasing the overall life of flash memory.
There are a lot of algorithms for static wear balance, and no algorithm is absolutely perfect. The algorithms of later generations are always further based on the previous algorithms, and different application scenarios and different requirements will lead to different algorithms.
An algorithm for tripling life: DiskMFR non-abrasion balance algorithm
Current garbage collection algorithms are basically designed around the idea of erasing each Block more evenly. These algorithms are based on the “assumption” that Block wear is exactly the same, but in fact, each page and Block wear state is different. When erasing all blocks on a flash memory evenly, Inevitably, some blocks will become Bad blocks first, while others will wear longer. This is determined by the wafer design process. Under current process conditions, it is not possible to ensure that every Block is identical, and there are bound to be some errors in the wafer, which are uncontrollable and randomly distributed.
New Nand Flash (model: The Erase time of each Block was different after 10 P/E operations. The different Erase times reflected the original state of each Block. The health state theory of short operation time Block is better than that of long operation time Block.

If the wear resistance of each Block is uneven, the artificial algorithm to keep the erasures of each Block consistent results does not prolong the overall life of the flash memory but just damages the optimal life of the flash memory.
The idea of the DiskMFR non-balance algorithm is: that the best work prevails. Breaking the previous balance algorithm based on the assumption of “the same life of each Block”, the real wear resistance of each page and Block is evaluated during the use process, so that blocks with strong wear resistance get more erasures, while those with poor wear resistance get corresponding protection. The erasure of each Block can be minimized only if no Block becomes a bad Block. For example, 100 blocks write 1TB of data and 1000 blocks write 1TB of data. If 100 blocks write 1TB of data and 100 blocks need to be erased 10 times, 1000 blocks need to be erased only once.
Another essence of the non-balance algorithm is: that when the UBER (Uncorrectable Bit Error Rate) of the Block reaches a certain threshold, the MLC mode will be automatically charged to the SLC mode.
The non-balance algorithm involves an important technical problem: how to judge the true wear resistance of flash memory (for example, page1 is 3000P/E cycle, page3 is 5000P/E cycle).
There are many methods to test the real wear-resisting degree of a page, which can be judged by a key indicator or multiple indicators. It can also be tested by accelerating the wear-resisting degree of a certain type of Nand Flash under high or low-temperature conditions in advance. Specific approaches are as follows:
By conducting destructive tests on a certain type of Nand Flash, and conducting the most thorough P/E tests on Nand Flash, recording accurate data of original bit error rate changes, uncorrectable bit error rate, and operation time, and establishing mathematical models among the three. The actual wear resistance of the page corresponding to different bit error rates (original bit error rate and low strength ECC) and operation time were defined, and the mathematical model was modified by accelerated testing under high-temperature conditions.
Although the complexity of the actual operation is high (testing is a very time-consuming process and requires constant modification of the mathematical model to make it more accurate), the actual results are far better than those without considering the actual wear resistance of the page. Technical progress often begins with detail and patience.
SSDs are the best practitioners of the barrel theory, and the overall lifetime of SSDS depends on the worst flash, so it’s how you select the most consistent flash that determines how long an SSD can last, otherwise, no matter how good an algorithm is, it’s going to lose out to the weakest flash.






